
Выход из кэша первого уровня
При выходе за границы кэш-памяти первого уровня, все четыре кривые лавинообразно "взлетают" (см. рис. graph 0x001), останавливаясь только тогда, когда размер обрабатываемого блока более чем в 1,5 раза превысит размер кэш-памяти первого уровня. Это обстоятельство слишком интересно, чтобы оставить его незамеченным. Почему именно полтора, а не, скажем, два или на худой конец три? На самом деле уже сам факт постепенного изменения скоростного показателя весьма знаменателен, ибо из самых общих рассуждений следует, что его градиент должен носить скачкообразный характер.
Рассмотрим полностью заполненный кэш и мысленно попытаемся загрузить еще одну кэш-строку. Для освобождения свободного места стратегия LRU предписывает вытолкнуть наиболее "дряхлую" кэш-строку, к которой дольше всего не происходило обращений. При последовательной обработке блока памяти это будет самая первая строка. Да, именно та, с которой начнется обработка следующей итерации цикла!
Поэтому, в очередном проходе цикла первой кэш-строки там уже не окажется и кэш-контроллер будет вынужден вновь обращаться к кэшу второго уровня, замещая самую "древнюю", на этот раз вторую по счету, строку (ведь свободных линеек в кэше по прежнему нет!) Соответственно, при обращении к следующей ячейке памяти ее вновь не окажется в кэше и кэш контроллер будет вынужден перезагружать все кэш-строки по цепочке, работая "вхолостую". Поскольку каждое обращение к памяти сопровождается кэш-промахом, размер обрабатываемого блока уже не критичен – превосходит ли он размер кэш-памяти на одну, две или десять кэш-линеек – безразлично, ибо избыток всего в одну-единственную кэш-линейку уже не обеспечивает ни одного кэш-попадания, – худшего результата просто не бывает!
Однако, вопреки всем доводам, полученный нами график с завидным упорством демонстрирует плавный, а отнюдь не скачкообразный градиент. Что это: ошибка эксперимента или ошибка рассуждений? Ошибка в рассуждениях действительно есть.
Ведь, вследствие ограниченной ассоциативности кэша, ячейки кэшируемой памяти связаны не с любыми, а со строго определенными кэш-строками.
Легче всего понять это обстоятельство на примере кэша прямого отображения. Вообразим себе такой полностью заполненный кэш. При обращении к следующей ячейке, кэш-котроллер загружает ее в кэш-строку под номером (cache_size+1) % cache_size == 1. Затем, при следующем проходе цикла, первая ячейка вновь идет в эту же самую строку (т. к. 1 % cache_size == 1), а вовсе не в самую "дневную" кэш-строку под "номером два". Да, строка "номер один" будет работать "вхолостую", но она не затронет всех остальных. Соответственно, если размер обрабатываемого блока превышает размер кэш-памяти на две строки, то количество "холостых" кэш-линеек будет равно двум. Наконец, при обработке блока данных, вдвое превышающего размер сверхоперативной памяти, кэш будет работать полностью вхолостую.
В наборно-ассоциативном кэше "насыщение" наступает гораздо раньше. И не удивительно – ведь каждая ячейка кэшируемой памяти может претендовать на одну из нескольких кэш-строк.
Рассмотрим кэш, состоящий из двух банков. При недостатке свободного места очередная считываемая ячейка идет в первую кэш-линейку первого банка, т.к. к ней дольше всего не было обращения, поэтому, при следующем проходе цикла первой обрабатываемой ячейки в кэш-памяти уже не окажется и ее придется перезагружать за счет вытеснения первую кэш-линейки второго банка.
В результате, вхолостую будет работать уже не одна, а целых две кэш-линейки и, если размер обрабатываемого блока превысит емкость кэш-памяти в полтора раза, кэш будет крутиться полностью вхолостую. Соответственно, четырех - ассоциативный кэш целиком насыщается при превышении размера кэш-памяти в 1.25 раза, а восьми - ассоциативный и того хуже – 1.125. Выходит, что высокая ассоциативность несет в себе не только плюсы, но и минусы и максимально достижимый размер кэшируемых данных составляет Кб.
(Замечание: это правило не обходится без исключений, – см. Особенности кэш-подсистемы процессоров P-II и P-III).
Однако все же вернемся к нашим баранам (в смысле графикам). Действительно, насыщение кэша наступает при обработке блока в 48 килобайт, т.е. при превышении емкости кэш-памяти на 16 килобайт, что практически (в смысле в пределах погрешности измерений) совпадает с размером одного кэш-банка (двух ассоциативный кэш процессора K6 содержит два банка по 16 Кб каждый), что и требовалось доказать.
Возьмем другой пример (см. рис. 0х022). Четырех ассоциативный шестнадцати килобайтный кэш процессора CELERON-300A, "сдыхает" ровно отметке в двадцать килобайт, что полностью соответствует приведенной выше формуле (), подтверждая ее справедливость.
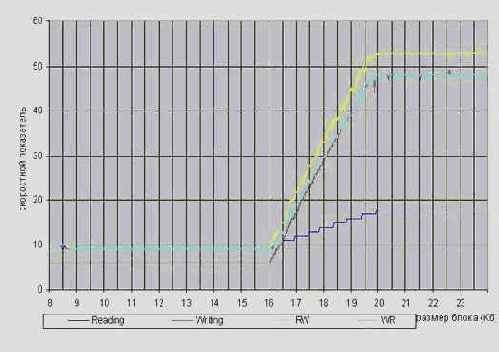
Рисунок 19 graph 0x029 Зависимость скорости обработки от размера блока на CELERON?300A