
Оптимизация штатных Си-функций для работы с памятью
Штатные библиотеки языка Си включают в себя большое количество функций, ориентированных на работу с блоками памяти. К ним, в частности, относятся: memcpy, memmove, memcmp, memset и др. В подавляющем большинстве случаях эти функции реализованы на ассемблере и достаточно качественно оптимизированы. Тем не менее, резерв производительности еще есть и путем определенных ухищрений можно сократить время обработки больших блоков памяти чуть ли не в несколько раз! Начнем?..
Оптимизация memcpy. Большинство реализаций функции memcpy выглядят приблизительно так: "while (count--) *dst++ = *src++". Этот код имеет по крайней мере три проблемы: перекрытие транзакций чтения/записи, невысокую степень параллелизма обработки ячеек и возможность пересечения обоих потоках в одном и том же DRAM-банке.
Перекрытие транзакций чтения/записи устраняется блочным копированием памяти через кэш-буфер: пусть один цикл считывает несколько килобайт источника в кэш, а другой цикл записывает содержимое буфера в приемник. В результате вместо чередования транзакций чтение – запись – чтение – запись… мы получаем две раздельных серии транзакций: чтение ? чтение ? чтение… и запись – запись – запись... Некоторое перекрытие транзакций на границах циклов все же останется, но если размер буфера составляет хотя бы 1 Кб этими издержками можно полностью пренебречь.
Параллелизм загрузки данных легко усилить, если обращаться к ячейкам с шагом равным размеру пакетного цикла чтения (см. "Параллельная обработка данных"). Для простоты можно остановится на шаге в 32 байта, но в критичных к быстродействию приложениях, оптимизируемых под процессоры старшего поколения (AMD Athlon, Pentium?4), эту величину рекомендуется определять автоматически или задавать опционально.
Пагубное влияние возможного пересечения потоков данных в одном DRAM-банке в данной схеме исчезает само собой, поскольку потоки обрабатываются последовательно, а не параллельно.
Образно выражаясь, можно сказать, что одним выстрелом мы убиваем сразу трех (!) зайцев, – копирование памяти через промежуточный буфер ликвидирует все слабые стороны алгоритма штатной функции memcpy, значительно увеличивая тем самым ее производительность.
Улучшенный вариант реализации memcpy может выглядеть, например, следующим образом:
for (a = 0; a < count; a += subBLOCK_SIZE)
{
for(b = 0; b < subBLOCK_SIZE; b += BRUST_LEN)
tmp += *(int *)((int)src + a + b);
memcpy((int*)((int)dst + a ),(int*)((int)src + a), subBLOCK_SIZE);
}
Листинг
29 [Memory/memcpy.optimize.c] Оптимизированная реализация memcpy
На AMD Athlon 1050/100/100/VIA KT133 оптимизированный вариант memcpy выполняется практически на треть быстрее и это очень хорошо! Правда, на P?III/733/133/100/I815EP прирост производительности намного меньше и составляет всего лишь ~10%. Увы, устраняя одни проблемы, мы неизбежно создаем другие. Предложенный способ оптимизации memcpy имеет как минимум два серьезных недостатка. Во-первых, увеличение количества циклов с одного до трех несет значительные накладные расходы, которых никакими ухищрениями невозможно избежать. Во-вторых, цикл, загружающий данные из оперативной памяти в кэш, фактически работает вхолостую, – запихивая полученные ячейки в неиспользуемую переменную, в то время как цикл, записывающий данные в память, вынужден повторно
обращаться к уже загруженным ячейкам. Т.е. count/BRUST_LEN ячеек копируются как бы дважды. К сожалению, первый цикл не может непосредственно записывать полученные ячейки в память, поскольку это неизбежно вызовет перекрытие шинных транзакций и лишь ухудшит производительность.
Ассемблерная реализация данного алгоритма, конечно, увеличит его быстродействие, но не намного. Гораздо лучший результат дает использование предвыборки (см. "Кэш. Предвыборка"), но это уже тем другого разговора.
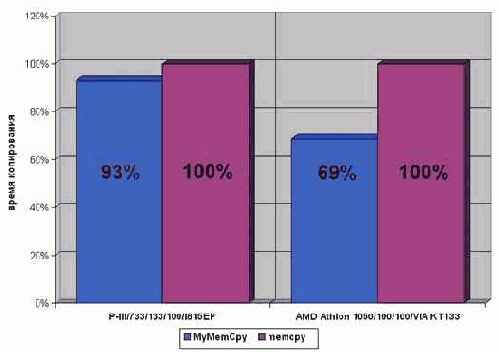
Рисунок 43 graph 0x021 Демонстрация эффективности параллельного копирования памяти.
Выигрыш особенно ощутим на процессорах Athlon – целых ~30% производительности
Оптимизация memmove Функция memmove, входящая в стандартную библиотеку языка Си, выгодно отличается от своей ближайшей родственницы memcpy тем, что умеет копировать перекрывающиеся блоки памяти. За счет чего это достигается? Если адрес приемника расположен "левее" источника (т.е. лежит в младших адресах) алгоритм копирования реализуется аналогично memcpy, поскольку ячейки памяти переносятся "назад", – в свободную неинициализированную область (см. рис 37 сверху). Единственное условие – количество ячеек памяти, переносимых за одну итерацию, не должно превышать разницу адресов приемника и источника. То есть, если приемник расположен всего в двух байтах от источника, переносить памяти двойными словами уже не получится!
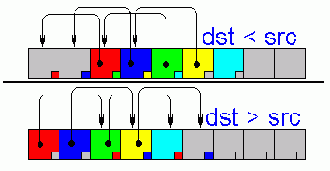
Рисунок 44 0х37 Копирование перекрывающихся блоков памяти. Если источник расположен правее приемника (верхний рисунок), то перенос ячеек памяти происходит без каких-либо проблем. Напротив, если источник расположен левее приемника (нижний рисунок), то перенос ячеек "вперед" приведет к затиранию источника
Гораздо сложнее справится с ситуацией, когда приемник расположен правее источника (т.е. лежит в старших адресах). Попытка скопировать память слева направо приведет к краху, т.к. перенос ячеек будет осуществляться в уже "занятые" адреса с неизбежным затиранием их содержимого. Попросту говоря, memcpy в этом случае будет работать как memset (см. рис. 37 снизу), что явно не входит в наши планы. Как же выйти из этой ситуации? Обратившись к исходным текстам функции memmove (в частности у Microsoft Visual C++ они расположены в каталоге \Microsoft Visual Studio\VC98\CRT\SRC\memmove.c), мы обнаружим следующий подход:
/*
* Overlapping Buffers
* copy from higher addresses to lower addresses
*/
dst = (char *)dst + count - 1;
src = (char *)src + count - 1;
while (count--) {
*(char *)dst = *(char *)src;
dst = (char *)dst - 1;
src = (char *)src - 1;
}
Листинг 30 Пример реализации функции memmove в компиляторе Microsoft Visual C++
Ага, память копируется с зада наперед, т.е. справа налево. В таком случае затирания ячеек гарантированно не происходит, но… за это приходится платить. Ведь ## как мы уже знаем, подсистема памяти оптимизирована именно под прямое чтение, и попытка погладить ее "против шерсти" ничего хорошего в плане быстродействия не несет. Насколько сильно это снижает производительность? На этот вопрос нет универсального ответа. В зависимости от особенностей архитектуры используемого аппаратного обеспечения эта величина может колебаться в несколько раз.
В частности, на Intel P-III/Intel 815EP обратное копирование памяти уступает прямому приблизительно в полтора раза. А вот на AMD Athlon/VIA KT133 разница в скорости между прямым и обратным копированием составляет всего ~2%, чем со спокойной совестью можно пренебречь. Тем не менее, компьютеры на основе Athlon/KT133 занимают значительно меньшую долю рынка, нежели системы на базе Intel Pentium, поэтому не стоит закладываться на такую конфигурацию.
При интенсивном использовании memmove общее снижение производительности может оказаться весьма значительным и неудивительно, если у разработчика возникнет жгучее желание ну хоть немного его поднять. Это действительно возможно сделать, достаточно лишь копировать память не байтами и даже не двойными словами, а… блоками с размером равным разнице адресов приемника и источника. Если размер блока составит хотя бы пару килобайт, память будет копироваться в прямом направлении, хотя и задом наперед. Как это можно реализовать на практике? Рассмотрим следующий пример, написанный на чистом Си без применения ассемблера. Для повышения наглядности отсюда исключен вспомогательный код, обеспечивающий, в частности, обработку ошибок и выравнивание стартовых адресов с последующим переносом "хвоста" (см. "Выравнивание данных").
int __MyMemMoveX(char *dst, char *src, int size)
{
char *p1,*p2;
int a,x=1;
int delta;
delta=dst-src;
if ((delta<1)) return -1;
for(a=size;a>delta;a-=delta)
memcpy(dst+a-delta,src+a-delta,delta);
return 0;
}
Листинг 31 Оптимизированный вариант реализации memmove, копирующий память блоками в прямом направлении, хотя и задом на перед
В сравнении со штатной memmove данная функция работает на 20% быстрее (если разница адресов источника и приемника не превышает размер кэш-памяти первого уровня) и на 30% при перемещении блоков памяти на большое расстояние (см. graph 15). Причем, это еще не предел, – переписав функцию MyMemMoveX на ассемблер, мы получим еще больший прирост производительности (см. так же "Параллельная обработка данных", "Кэш. Предвыборка").
Разумеется, если разница адресов источника и приемника невелика (менее килобайта), то "обмануть" систему не получится, и память будет копироваться скорее в обратном направлении, чем в прямом. При этом, накладные расходы на организацию цикла поблочного копирования вызовут значительное снижение производительности, проигрывая штатной memmove в два и более раз. Поэтому, на область применения MyMemMoveX наложены определенные ограничения.
Хорошо, но ведь бывают же такие случаи, когда перекрывающиеся области необходимо копировать именно "вперед"? Допустим, у нас имеется поток данных, не поддерживающий позиционирование указателя или, скажем, весь блок памяти на момент начала копирования целиком еще недоступен. Вот вполне жизненный пример (из практики автора) – при перемещении фрагментов изображения в графическом редакторе техническое задание требовало выполнять обновление изображения от начала блока к концу. (Дабы пользователь мог приступать к работе с изображением, не дожидаясь, пока блок будет перемещен целиком). Причем, использовать ссылочную организацию данных запрещалось. (Кто сказал, что это глупость? нет, это не глупость, это ? техническое задание).
Тупик? Вовсе нет! Напротив, – возможность поразмять мозги ( ну не все же время рисовать интерфейсы в Visual Studio).
Первое, что приходит на ум, – перенос памяти через промежуточный буфер. Все идея реализуется тривиальным кодом вида:
mymovemem(char *dst, char *src, int size)
{
char *tmp;
tmp=malloc(BLOCK_SIZE);
memcpy(tmp, src, BLOCK_SIZE);
memcpy(dst, tmp, BLOCK_SIZE);
}
Листинг 32 Вариант реализации memmove с переносом памяти через промежуточный буфер
Гуд? Да какой там гуд!!! Во-первых, предложенный алгоритм удваивает
количество потребляемой памяти, что в ряде случаев просто неприемлемо; во-вторых, он в два раза увеличивает время копирования и, наконец, в-третьих, он не решает задачи, поставленной в ТЗ. Ведь обновление начала изображения начнется не сразу, а через довольно продолжительное время, в течение которого будет заполняться временный буфер. Так что не стоит этот алгоритм и обсуждать!
Но, постойте, зачем нам копировать весь перемещаемый блок в промежуточный буфер целиком? Достаточно сохранить лишь ту его часть, которая затирается выступающим влево "хвостом". Т.е. максимально разумный размер буфера равен dst – src. Рассмотрим упрощенный вариант алгоритма прямого перемещения памяти, использующий два таких буфера. Назовем его четырехтактным потоковым алгоритмом копирования памяти. Почему "четырехтактным" станет ясно ниже.
Итак, такт первый. memcpy(BUF_1, dst, dst - src)
– мы сохраняем память приемника, поскольку, этот фрагмент будет затерт в следующем такте (см. рис. 36).
Такт второй: memcpy(dst, src, dst - src)
– мы копируем (dst – src) байт из источника в приемник, не беспокоясь о затираемой памяти, т.к. она уже сохранена в буфере.
Такт третий: memcpy(BUF_2, dst + (dst – src), dst – src) – сохраняем следующую порцию данных приемника во втором промежуточном буфере.
Такт четвертый: memcpy(dst+ (dst – src), BUF_1, dst – src) – "выливаем" содержимое буфера BUF_1 на положенное место (оно только что было сохранено в BUF_2).
Все! Первый буфер освобождается и можно смело переходить к такту I, – "рабочий цикл" нашего "движка" завершен.
Как нетрудно убедиться, копирование происходит только в прямом направлении, причем память приемника обновляется от начала к концу маленькими порциями по (dst – src) байт. (При "мышином" перетаскивании областей изображений в графическом редакторе они, действительно, недалеко уползают за один шаг; кстати, Microsoft Paint (графический редактор из штатной поставки Windows) при перетаскивании изображений перемещает память именно memmove, поэтому жутко тормозит даже на P-III).
Причем, если разница адресов источника и приемника составляет порядка 4-8 Кб, то, несмотря на двойной перегон памяти к буферам и обратно, предложенный алгоритм даже обгоняет
memmove на 10%, – во всяком случае на P-III (см. рис. graph 18). А на AMD Athlon/VIA KT133 разница достигает аж 1,7 крат (в пользу нашего алгоритма, естественно), впрочем, это отнюдь не показатель крутости алгоритма, – просто VIA KT133 так уж устроен.
А теперь давайте подумаем: можно ли уменьшить количество буферов с двух до одного? Разумеется, да, – ведь на момент завершения второго такта, регион [src[0]…src[dst-src]] (на рис. 36 он закрашен красным цветом) уже свободен и может использоваться для временного хранения данных. Однако тут есть один подводный камень, – если адреса "своих" временных буферов мы можем выбирать самостоятельно с учетом архитектуры и организации DRAM, то адрес источника нам дается "извне" со всеми отсюда вытекающими… Разумеется, ничего невозможно нет и при желании обойтись всего одним буфером при не сильно худшей эффективности – вполне возможно, но это значительно усложнит алгоритм и снизит его наглядность. А алгоритм, надобно сказать, и без того не слишком прозрачен (см. листинг…MyMemMove)
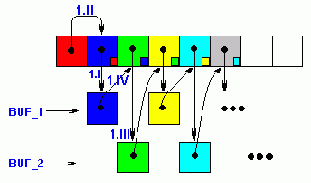
Рисунок 45 0x036 "Четырехтактный" алгоритм прямого переноса памяти с использованием двух промежуточных буферов
#define BUF_SIZE 256*K
int __MyMemMove(char *dst, char *src, int size)
{
char BUF_1[BUF_SIZE];
char BUF_2[BUF_SIZE];
char *p1, *p2;
int a,x = 1;
int delta;
delta=dst-src;
if ((delta>BUF_SIZE) || (delta<1)) return -1;
p1 = BUF_1;
p2 = src;
for(a = 0; a<size/delta; a++)
{
memcpy(p1,dst,delta);
memcpy(dst,p2,delta);
if (x)
{
p1 = BUF_2; p2 = BUF_1;
x =
0;
}
else
{
p1 = BUF_1; p2 = BUF_1;
x =
1;
}
dst +=
delta;
}
return 0;
}
Листинг 33 Вариант реализации четырехтактного алгоритма переноса памяти только в прямом направлении с использованием двух промежуточных буферов
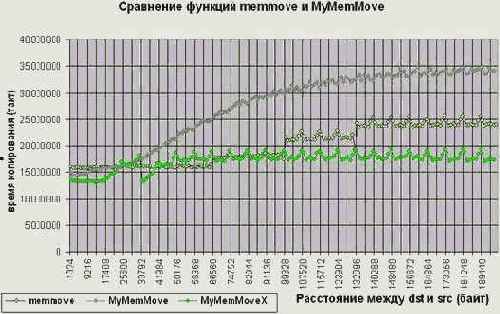
Рисунок 46 graph 15 Демонстрация эффективности различных алгоритмов переноса памяти
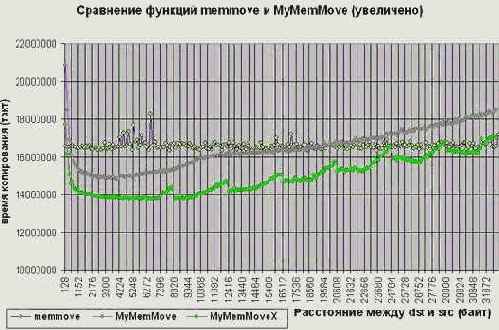
Рисунок 47 graph 18 Демонстрация эффективности различных алгоритмов переноса памяти (увеличено)
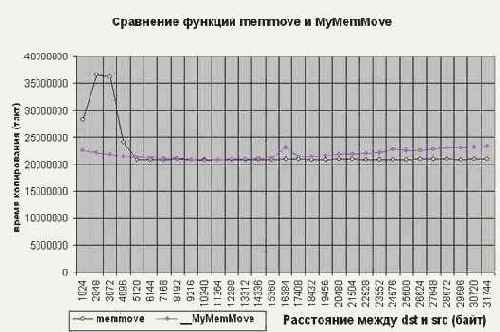
Рисунок
48 graph 16 Сравнение функций memmove и MyMemMove на системе AMD Athlon 1050/100/100/VIA KT133
Оптимизация функции memcmp
Несмотря на то, что функция memcmp не относится к числу самых популярных (так, в MSDN memcpy упоминается 500 раз, а memcmp и memmove – всего 150 и 50 раз соответственно) это еще не дает оснований пренебрегать качеством ее реализации. Начнем с анализа штатных библиотек вашего компилятора. В большинстве случаев сравнение блоков памяти осуществляется приблизительно так:
void * __cdecl _memccpy (void * dest, const void * src, int c, unsigned count)
{
while ( count && (*((char *)(dest = (char *)dest + 1) - 1) =
*((char *)(src = (char *)src + 1) - 1)) != (char)c ) count--;
return(count ? dest : NULL);
}
Листинг 34 Реализация memcmp в компиляторе Microsoft Visual C++ 6.0
Фи! Тормозное побайтное сравнение безо всяких попыток оптимизации! Правда в комплект поставки Visual C++ входит и ассемблерная реализация той же самой функции (ищите ее в каталоге \SRC\Intel). Ну-ка, посмотрим, что там (по соображениям экономии места исходный текст не приводится): ага, если оба указателя кратны четырем, сравнение ведется двойными словами (что намного быстрее) и лишь в противном случае – по байтам. Гуд? А вот и не гуд! Кратность начальных адресов – условие вовсе необязательное для 32-разрядного сравнения (строго говоря, процессоры серии 80x86 вообще не требуют осуществлять выравнивания, просто небрежное отношение с не выровненными адресами может несколько снизить быстродействие – подробнее см. "Выравнивание адресов"). Если три младших бита обоих указателей равны, функция может выровнять их и самостоятельно, просто сместившись на один, два или три байта "вперед".
Впрочем, эти рассуждения все равно беспредметны, поскольку, в режиме оптимизации по скорости (ключ "/O2") Microsoft Visual C++ отказывается от использования ряда библиотечных функций и заменяет их intrinsic-ами (см. "pragma intrinsic" в документации по компилятору). Забавно, но разработчики компилятора, по-видимому, сочли, что выполнять множество проверок и "тянуть" за собой несколько вариантов реализации функции сравнения будет нерационально (?) и потому они ограничились одним универсальным решением – тривиальным побайтовым сравнением. Неудивительно, что после такой "оптимизации" быстродействие memcmp значительно ухудшилось.
Чтобы запретить компилятору самовольничать, – используйте прагму "function" с указанием имени функции, например, так: "#pragma function(memcmp)". В частности, на P-III это ускорит выполнение функции приблизительно на 36%! Правда, на Athlon разница в производительности будет существо меньше – порядка 10%. Кстати, в защиту Microsoft можно сказать, что ее реализация memcmp на 20%-30% быстрее, чем у Borland C++ 5.5.
Но и это еще не предел!
Для memcmp (как и для большинства остальных функций, работающих с памятью) актуальна проблема оптимального чередования DRAM-банков (см. "Стратегия распределения данных по DRAM-банкам"). Если оба сравниваемых блока начинаются с различных страниц одного и того же банка, время доступа к памяти существенно замедляется. Поэтому, мы должны уметь отслеживать такую ситуацию, при необходимости увеличивая один из указателей на длину DRAM-страницы. Это повысит скорость выполнения функции приблизительно на 40% на P-III и на целых 60%-70% на AMD Athlon (да-да, практически в три раза!). Правда, тут есть одно "но". Память должна обрабатываться не байтами, а двойными словами, в противном случае прирост производительности составит всего лишь 5% для P-III и немногим менее 30% для AMD Athlon.
Хорошо, а если адреса сравниваемых блоков к нам поступают "извне" и скорректировать их невозможно? Существует два пути: смириться с низкой производительностью или… сравнивать не сами блоки памяти, а их контрольную сумму. Конечно, теоретически не исключено, что контрольные суммы различных блоков памяти "волшебным" образом совпадут, но в подавляющем большинстве случаев эта вероятность настолько мала, что ей вполне можно пренебречь. К тому же, считать контрольную сумму всего блока абсолютно необязательно – достаточно ограничиться одной DRAM-страницей (можно в принципе и меньшей величиной, главное, чтобы переключения между страницами одного банка происходили не слишком часто). За счет сокращения количества параллельно обрабатываемых потоков данных с двух до одного, хеш-алгоритм работает намного быстрее штатной функции сравнения памяти, обгоняя ее на ~35% и ~55% на P-III и AMD Athlon соответственно. Правда, при оптимальном чередовании банков памяти, хеш-алгоритм все же проигрывает функции, сравнивающей память двойными словами. Причем, если на P-III хеш-алгоритм отстает от нее всего на 1%, то на AMD Athlon разрыв в производительности достигает целых 10%!
Таким образом, хеш-алгоритм целесообразно использовать только
при неоптимальном чередовании DRAM-банков. Впрочем, категоричность этого утверждения смягчает одна оговорка. Если мы сократим длину хешируемого блока до величины пакетного цикла обмена, на P-III мы получим практически 60% выигрыш в производительности, обогнав самый быстрый алгоритм двойных слов более чем на 20%! Ценой же за это станет постоянное переключение DRAM-страниц и, как следствие, потеря возможности противостоять неблагоприятному чередованию банков памяти. Однако такой значительный прирост скорости стоит того! Увы, этот эффект имеет место лишь на Intel и не переносим на AMD/VIA. С другой стороны, Pentium?ам принадлежит более половины компьютерного рынка и оснований для отказа от предложенного трюка, в общем-то, нет. Тем более что даже на AMD Athlon он (хеш-алгоритм) работает значительно быстрее штатной функции сравнения памяти. Один из возможных вариантов его реализации будет выглядеть так:
for(a=0;a<BLOCK_SIZE;a+=DRAM_PG_SIZE)
{
crc_1=0; crc_2=0;
for(b = 0; b < DRAM_PG_SIZE; b += sizeof(int))
// Внимание! Это очень слабый алгоритм подсчета CRC
// и его можно использовать _только_ для демонстрации
crc_1 += *(int*)((int)p1+a+b);
for(b = 0; b < DRAM_PG_SIZE; b += sizeof(int))
crc_2 += *(int*)((int)p2+a+b);
if (crc_1 != crc_2)
break; // Если CRC не совпадают, следовательно,
// блоки памяти различны.
// При необходимости можно вызвать
// memcmp(p1+a, p2+a, BLOCK_SIZE-a)
// для уточнения результата
}
Листинг 35 Оптимизированный вариант реализации memcmp с использованием хеш-алгоритма
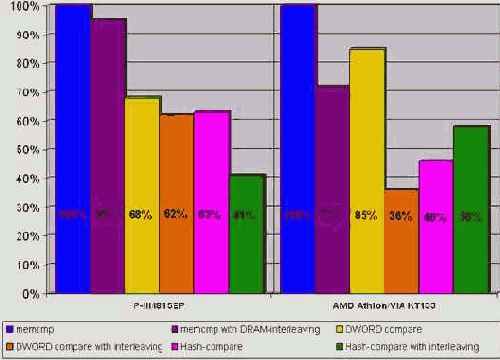
Рисунок 49 graph 19 Демонстрация эффективности различных алгоритмов сравнения блоков памяти.
Оптимизация memset. Нет никаких идей по поводу оптимизации данной функции.
Особое замечание по функциями Win32 API В win32 API входит множество функций для работы с блоками памяти, среди которых присутствуют и прямые эквиваленты штатных функций языка Си: CopyMemory (эквивалент memcpy), MoveMemory (эквивалент memmove) и FillMemory
(эквивалент memset).
Возникает вопрос: чем лучше пользоваться – функциями операционной системы или функциями самого языка? Ответ: компания Microsoft намеренно заблокировала возможность использования функций ядра операционной системы, включив в заголовочные файлы WINBASE.H и WINNT.H следующий код:
#define MoveMemory RtlMoveMemory
#define CopyMemory RtlCopyMemory
#define FillMemory RtlFillMemory
#define ZeroMemory RtlZeroMemory
Листинг 36 Фрагмент WINBASE.H
#define RtlEqualMemory(Destination,Source,Length)
(!memcmp((Destination),(Source),(Length)))
#define RtlMoveMemory(Destination,Source,Length)
memmove((Destination),(Source),(Length))
#define RtlCopyMemory(Destination,Source,Length)
memcpy((Destination),(Source),(Length))
#define RtlFillMemory(Destination,Length,Fill)
memset((Destination),(Fill),(Length))
#define RtlZeroMemory(Destination,Length)
memset((Destination),0,(Length))
Листинг 37 Фрагмент WINNT.H
Вот это номер! Оказывается, функции семейства xxxMemory представляют собой макро-переходники к штатным функциям языка! Причем, это отнюдь не корпоративная тайна, а вполне документированная особенность, косвенно подтверждаемая Platform SDK. При внимательном изучении описания функции MoveMemory мы обнаружим следующее:
Quick Info
Windows NT: Requires version 3.1 or later.
Windows: Requires Windows 95 or later.
Windows CE: Unsupported.
Header: Declared in winbase.h.
Ну и что здесь особенного? А вот что: строка "Import Library" отсутствует! Следовательно, функция MoveMemory целиком реализована во включаемом файле WINBASE.H, о чем Microsoft нас и предупреждает.
Но это еще не конец истории. Скорее, только ее начало.
Давайте, воспользовавшись утилитой DUMBDIN, посмотрим на список функций, экспортируемых "ядреной" библиотекой операционной системы – файлом KERNEL32.DLL. Вопреки логике и здравому смыслу мы обнаружим следующее:
598 255 RtlFillMemory (forwarded to NTDLL.RtlFillMemory)
599 256 RtlMoveMemory (forwarded to NTDLL.RtlMoveMemory)
600 257 RtlUnwind (forwarded to NTDLL.RtlUnwind)
601 258 RtlZeroMemory (forwarded to NTDLL.RtlZeroMemory)
Выходит, что функции RtlMoveMemory, RtlFillMemory и RtlZeroMemory в ядре системы все-таки есть! Причем, это не просто "заглушки", все тело которых состоит из одного оператора return, а вполне работоспособные функции. Чтобы убедиться в этом, достаточно вызвать любую из функций напрямую в обход SDK. Одина из возможных реализаций приведена ниже (обработка ошибок по соображениям наглядности не приведена):
HINSTANCE h;
#undef RtlMoveMemory
void (__stdcall *RtlMoveMemory)(void *dst, void* src, int count);
h=LoadLibrary("KERNEL32.DLL");
RtlMoveMemory = (void (__stdcall *)(void *dst, void* src, int count))
GetProcAddress(h, "RtlMoveMemory");
Листинг 38 Пример вызова RtlMoveMemory явной компоновкой
Впрочем, использовать RtlMoveMemory вместо memmove, – не очень хорошая идея и Microsoft не зря заблокировала ее вызов. Функция RtlMoveMemory совершенно отвратительно оптимизирована. Во-первых, она не выравнивает адреса перемещаемых блоков памяти, а, во?вторых, перекрывающиеся блоки памяти в случае src < dst копирует по байтам, что нельзя признать оптимальным.
На платформе P-III/733/133/100/I815EP функция RtlMoveMemory проигрывает штатной функции memmove компилятора Microsoft Visual C++ 6.0 чуть ли не в полтора раза! Правда, на AMD Athlon 1050/100/100/VIA KT133 ситуация диаметрально противоположная, – здесь функция memmove отстает от своей конкурентки, причем весьма значительно, – на целых ~30%!
С функцией FillMemory ситуация более постоянна. На всех системах она показывает ничуть не худший результат, чем штатная функция языка memset и потому совершенно все равно какую из них использовать. Аналогичная картина наблюдается и с функцией ZeroMemory, являющиеся прямой родственной FillMemory, но заполняющий блок памяти нулями, а не произвольным значением. С другой стороны, с практической точки зрения "FillMemory" на целых три символа длиннее, чем "memset" и потому использование последней все же предпочтительнее. Впрочем, эта оценка достаточна субъективна. Встречаются эстеты, которые находят, что "FillMemory" выглядит красивее, чем "memset" и к тому же намного легче читается. Что ж, выбирайте то, что вам больше по душе!
Может показаться, что при инициализации множества крошечных блоков памяти использование FillMemory повлечет за собой значительные накладные расходы на многократный вызов функции. (memset в отличие от нее может быть непосредственно вживлена в исполняемый код как inline, – обычно она и вживляется). На самом же деле, современные процессоры так быстры, что временем вызова функции можно полностью пренебречь. Разница в производительности memset и FillMemory едва ли превысит несколько процентов, что практически не скажется на общем быстродействии программы.
Вы, наверное уже обратите внимание, что в списке win32 API функций отсутствует какой бы то ни было аналог memcmp. Это действительно странно, поскольку в файле WINNT.H такая функция все-таки есть:
#define RtlEqualMemory(Destination,Source,Length)
(!memcmp((Destination),(Source),(Length)))
А в среди функций, экспортируемых NTDLL.DLL есть RtlCompareMemory, которая, как нетрудно догадаться из нее названия, именно та, которая нам и нужна! Причем, в отличие от функции RtlMoveMemory, функция сравнения памяти достаточно прилично оптимизирована и даже обгоняет штатную функцию memcmp компилятора Microsoft Visual C++ 6.0 (см.
рис. graph 23). На P-III/733/133/I815EP разрыв в производительности составляет ~40%, а на AMD Athlon 1050/100/100/VIA KT133 – ~15%.
К сожалению, функция RtlCompareMemory не реализована на Windows 9x и программа, ее использующая, будет работать только под NT/W2K. Конечно, можно распространять свой продукт вместе с библиотекой NTDLL.DLL, позаимствованной, из каталога WINNT\SYSTEM (только переименуйте ее во что ни будь другое, т.к. в Win9x уже есть "своя" NTDLL.DLL), но не проще ли самостоятельно реализовать memcmp, тем более, что в этом нет ничего сложного? "Изюминка" функции RtlCompareMemory заключается в том, что в отличие от memcmp она сравнивает память не байтами, а двойными словами. Вот и весь секрет ее производительности!
Заключительный вердикт: при разработке критичных к быстродействию приложений лучше всего использовать собственные реализации функций, работающих с памятью, оптимизированных с учетом рекомендаций, приводимых в данной главе. И штатные функции языка, и функции операционной системы в той или иной степени не оптимальны.
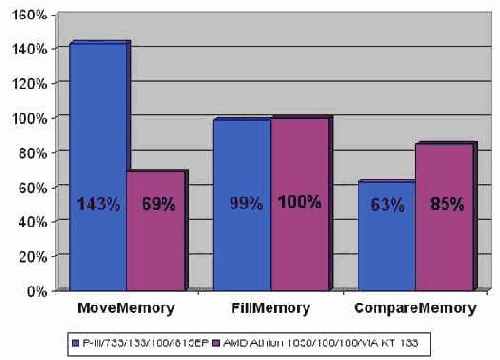
Рисунок 50 graph 23 Сравнительная характеристика шатанных функций компилятора Microsoft Visual C++ и эквивалентных им функций операционной системы. Кстати, все они в той или иной степени не оптимальны