
Обсуждение результатов тестирования
Итак, тестирование началось… Прогон "подопытных" примеров на процессорах Intel Pentium-III 733 и AMD Athlon 1.400 (см. рис. 1, рис. 2) говорит о достаточно высоком качестве кодогенерации современных компиляторов. В среднем (за вычетом особо оговариваемых исключений) производительность откомпилированных программ лишь на 20%?30% уступает вручную оптимизированному ассемблеру. Конечно, это весьма внушительная величина (особенно, если вспомнить, что эталонная ассемблерная программа достаточно далека от идеала). Эй, кто там говорил, что машинная оптимизация уступает человеку не более одно-двух процентов?! А ну подать сюда этого человека!
С другой стороны, разрыв производительности (за редкими исключениями) все же не настолько велик, чтобы перенос программы на ассемблер приводил к качественным изменениям.
А теперь обо всем этом подробнее. Как и следовало ожидать, наибольший разрыв в производительности наблюдается на копировании памяти. Впрочем, этот разрыв значительно сокращается с ростом тактовой частоты процессора. Если на P-III 733 наименьшее отставание составило целых 25%, то на Athlon 1.400 – всего 9%! Едва ли последняя цифра нуждается в комментариях – Microsoft рулит и жизнь прекрасна. Быстрота современных процессоров, помноженная на мощь современных компиляторов – и никаких ассемблерных вставок! Конечно, не все компиляторы одинаково хороши. Так, WATCOM – вообще в осадке; Borland уверенно держит позиции на Intel, но генерирует несколько неоптимальный код с точки зрения AMD.
С поиском минимума все компиляторы справились одинаково хорошо, а Microsoft Visual C++ вообще построил идеальный по своей красоте код, лишь из-за досадной случайности не дотянувшийся до 100% результата, – начало цикла пришлось на наихудший с точки зрения микропроцессора адрес: 0х4013FF. "Благодаря" этому каждая итерация облагается несколькими штрафными тактами, что, в конечном счете, выливается во вполне весомые потери. Чаще всего, впрочем, судьба оказывается не столь жестока, и код, сгенерированный компилятором, исполняется достаточно эффективно.
Однако нет никаких гарантий, что даже малейшее изменение программы, (да, да, – в том числе и выкидывание лишнего кода!), не ухудшит ее производительности (причем, под час весьма значительно). Увы, в этом смысле компиляторы все еще тупы до безобразия. Они либо вовсе не выравнивают переходы, либо выравнивают все
переходы, что неоправданно увеличивает размер программы и нередко дает обратный эффект, многократно снижая ее производительность (если программа в результате такого распухания не поместится в кэш). Между тем, правильное решение – выравнивать лишь часто выполняемые переходы, в частности циклы, но – увы – ни в одном известном мне компиляторе это не реализовано.
Заметно лучше сложилась ситуация с сортировкой. Компилятор Microsoft Visual C++ отстает от ассемблерного кода всего лишь на 13%-14%. За ним с минимальным отрывом идет Borland C++ со своими 15% и 24% для Athlon 1.400 и P-III 733 соответственно. Последнее место занимает WATCOM, ни в чем не уступающий Borland'у на Pentium'e, но безапелляционно сдающий свои позиции на Athlon'е. Ну не виноват он, что создавался в ту далекую эпоху, когда и процессоры, и техника оптимизации были совсем другими! В целом, WATCOM неплохой, но безнадежно устаревший оптимизатор, и любовь к нему (у тех, у кого она имеется) не должна слепить глаза, сегодня WATCOM'ом – уже не самый лучший выбор.
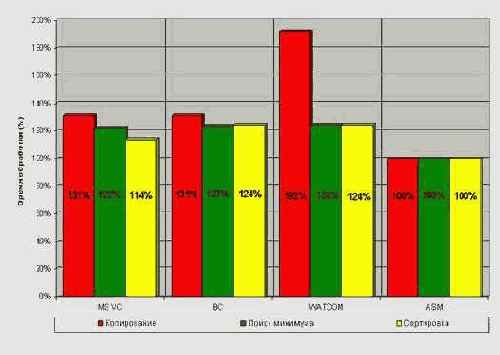
Рисунок 3 0х001 Сравнение качества машинной кодогенерации по скорости на Intel P-III 733
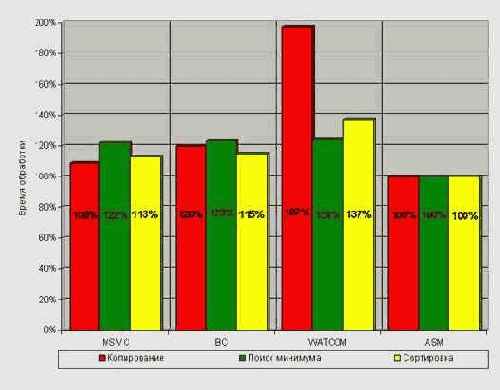
Рисунок 4 0х002 Сравнение качества машинной кодогенрации по скорости на AMD Athlon-1.400
Перейдем теперь к сравнению размера откомпилированного и ассемблерного кода. Первое, что бросается в глаза (см. рис. 3), – весьма внушительный отрыв Microsoft Visual C++ от своих конкурентов. Однако и он отстает от "ручного" кода, не дотягивая по меньшей мере 23%. Причем, по мере упрощения задач этот разрыв резко увеличивается, достигая в случае примера с копированием памяти целых 76%! Ух, ты! Ассемблерная реализация оказалась практически вдвое короче!
У конкурентов же ситуация еще хуже. Значительно хуже. Грубо говоря, можно утверждать, что перенос программы на ассемблер как минимум сокращает ее размер раза в полтора-два. Тем не менее, два раза – это не триста и с этим вполне можно жить.
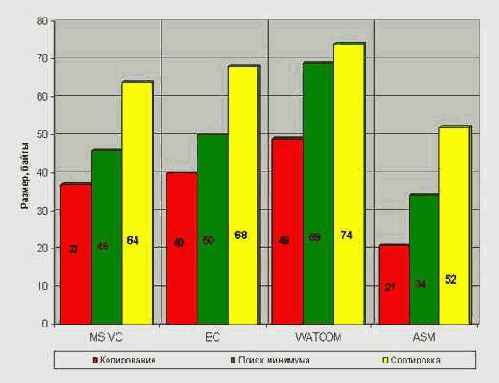
Рисунок 5 0x003 Сравнение качества машинной кодогенерации по размеру